Let's start with a fundamental concept and then dive deep into the project:
What is Prompt Compression?
Prompt compression is the method to reduce the prompt length before feeding it to large language models(LLM)
Objective: The main objective of this technique is to cut the prompt length without losing the quality of the data, lower the costs, reduce inference time, and sometimes improve efficiency.
The entire project code is available here: Github
Two types of Methods:
- LLMLingua
- LongLLMLingua
LLMLingua and LongLLMLingua are techniques developed and made open-source by Microsoft Research.
Let us understand each and their Importance:
LLMLingua: LLMLingua uses Large language models(LLMs) as compressors, as these LLMs summarize, process, and understand information well. its goal is to compress the lengthy prompts without losing the most important information.
LongLLMLingua: LongLLMLingua was built on top of LLMLingua and aimed to solve the problems of very long prompts that LLMs have, as their context window is small and sometimes it is very difficult to remember the long context. In a nutshell, it deals with extremely long contexts and solves the difficulties of working with long contexts.
Difference between LLMLingua and LongLLMLingua: LLMLingua is used for the optimization of prompts, while LongLLMLingua is an advanced tool designed to deal with very long contexts.
Benefits: It significantly reduces the context length, and it is very useful when dealing with expensive LLMs which eventually cut costs. One of the main problems we face with LLMs is inference time, which reduces inference time exponentially. In many cases, performance may even improve using prompt compression.
Use Cases: Both LLMLingua and LongLLMLingua are extremely beneficial where LLMs get lengthy prompt applications like Summarization, Fact Checking, RAG, etc.
Today, we will look at the prompt compression from the perspective of the RAG pipeline.
RAG (Retrieval Augmented Generation): RAG is a technique to improve the output of large language models (LLMs). It uses a custom knowledge base like web data, documents, and databases to generate the response from relevant documents for the given query. LLMs may not be trained on the most recent and real-time information. RAG is the best choice instead of fine-tuning LLMs on the knowledge base, which saves computation costs.
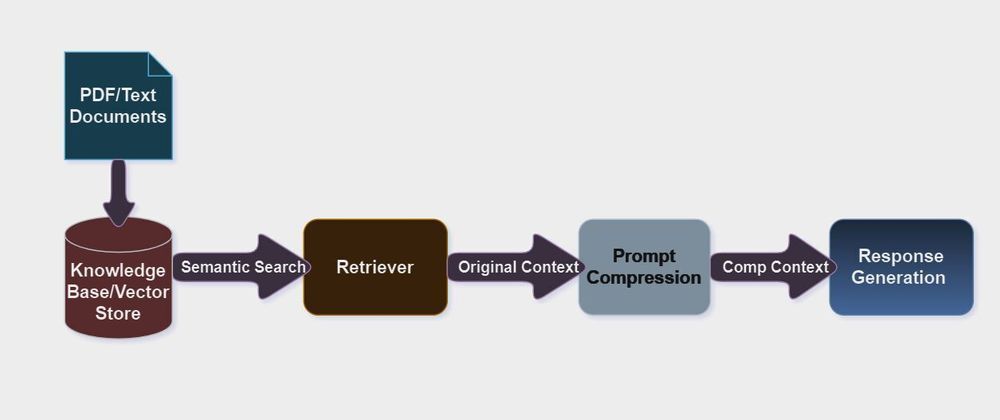
Components of RAG: RAG consists of a document reader and loader to extract information from documents, a retriever to fetch the most relevant documents using semantic search, a vector store index to store and retrieve efficiently, and a response generator to produce output in JSON format using LLMs.
Steps Implemented in our RAG Pipeline:
Document Reader: In this project, we have used llama-index PDFReader to extract the text from PDF/Text documents, which stores the data in the form list of documents and is easy to feed into any workflow. As it uses pypdf library internally, pdf text extraction is very efficient.
In this project, We have utilized 'Power of The Subconscious Mind - Joseph Murphy.pdf' as a sample document for testing, all the questions are formatted based upon this document.
VectorStore: We are utilizing llama-index Vectorstoreindex, to index both embeddings and documents to retrieve later using similarity search. vector stores are designed to store and organize our documents efficiently.
Embeddings: We have incorporated OpenAI embeddings. These embeddings are very powerful in creating semantic relationships.
it converts all the text documents to high-dimensional numerical vectors where we can use the power of linear algebra, as LLMs process only numbers. Embeddings are the key and can influence the accuracy of the LLM.
Retrieval: Our next step is to create a retrieval object on top of the vector store index. This object is used to retrieve the relevant information from the vector store index given query, similarity search method, and Top_k(No of documents to fetch), etc.
We will explore prompt compression with two methods: one is LLMLingua with OpenAI models, and the other uses LLAMA-Index's LongLLMLingua.
1. LLMLingua and OpenAI models:
Prompt compression: Prompt compression reduces the cost and prompt tokens exponentially without compromising the quality of information. by default, LLMLingua uses the llama-2-7b model for prompt compression we can also use other open source from huggingface and openai models. This technique is very useful for LLMs with small context windows which can not afford long contexts.
Response generation: To generate the natural language response, we use OpenAI GPT-3.5-Turbo model, which utilizes a compressed prompt as input. This model excels at understanding and generating natural language.
Questions Asked:
Query: "How can I use the full potential of my Subconscious mind?"
Prompt Compression Ratio:
Original Prompt: 1429
Compressed Prompt: 502
Compressed Ratio: 2.85x
Output response:
To use the full potential of your subconscious mind, you can follow these steps:
1. Avoid mental confusion or excessive effort, as it can block your subconscious mind. Accept ideas easily and let your subconscious mind work to execute them.
2. Think and plan independently, not relying solely on traditional methods. Believe that there is always an answer and solution to every problem.
3. Do not be overly concerned with negative thoughts or emotions. Trust in the power of your subconscious mind and affirm that the right action is being taken.
4. Focus on health and wealth, as the state of your mind influences your physical and financial well-being.
5. Use your imagination to visualize your desires clearly and positively. Avoid conflicting thoughts in your subconscious mind.
6. Practice positive affirmations and visualization techniques to reinforce your goals and desires.
7. Keep fear, worry, and doubt at bay by holding onto your vision and goals. Tap into the infinite power within you through positive thinking and confidence.
8. Establish good habits by repeating positive thoughts and actions until they become automatic in your subconscious mind.
9. Choose good habits over bad habits, and incorporate prayer as a positive habit.
10. Believe in the power of faith and visualization, as your subconscious mind will manifest what you focus on in your conscious mind.
11. Recognize that the only obstacle to your success is your own thoughts and mental images. Stay positive and focused on your goals to unlock the full potential of your subconscious mind.
Query: "What is the difference between the conscious mind and the subconscious mind?"
Prompt Compression Ratio:
Original Prompt: 1796
Compressed Prompt: 532
Compressed Ratio: 3.38x
Output response:
The conscious mind is the part of the mind that is aware of thoughts, feelings, and perceptions and is responsible for decision-making and rational thinking. The subconscious mind, on the other hand, operates below the level of conscious awareness and influences behavior, emotions, and beliefs based on past experiences and conditioning. The subconscious mind does not reason or argue, but rather accepts and acts upon the beliefs and thoughts that are planted in it
2. Llama-index Postprocessor LongLLMLingua:
Prompt compression: In the second part of this project, we used the llama-index-postprocessor-LongLLmLingua tool that compresses very long context prompts by not losing any of the essence of the information — the tool to use for any RAG applications with long contexts as input. This tool also allows the inference time to be reduced. This is crucial for LLMs in production because sometimes you need to use an LLM with inference time that is slow for the problem you’re solving. This drastically reduces the inference time of the LLM.
Response generation: The llama-index response synthesizer is used for user query and a given list of text documents. In a query engine, the first-step nodes get retrieved from a retriever and then the response synthesizer is called. The response format of the response synthesizer is a response object.
Questions Asked:
Query: "How can I use the full potential of my Subconscious mind?"
Prompt Compression Ratio:
Original Tokens: 1711
Compressed Tokens: 180
Compressed Ratio: 9.51x
Output Response:
Keep your conscious mind busy with positive and optimistic thoughts, and your subconscious mind will faithfully manifest those thoughts into reality. Imagine and feel the desired outcome or solution to your problem, and your subconscious mind will accept and bring it to fruition.
Query: "What is the difference between the conscious mind and the subconscious mind?"
Prompt Compression Ratio:
Original Tokens: 2110
Compressed Tokens: 83
Compressed Ratio: 25.42x
Output response:
The conscious mind and the subconscious mind are two different aspects of our mental processes. The conscious mind is responsible for our awareness and rational thinking. It is the part of our mind that we actively use to make decisions, solve problems, and engage in logical reasoning. On the other hand, the subconscious mind operates below the level of conscious awareness. It is responsible for storing and processing information that we are not actively thinking about. The subconscious mind influences our thoughts, emotions, and behaviors, often without us realizing it. It is also believed to play a role in shaping our beliefs, habits, and automatic responses.
Conclusion: From the generated responses section, we see that sometimes the quality of the response is even better than the original responses with the prompt, as we see from some questions asked. From this observation, LLMLingua can enhance not only the performance of prompt generation but also the performance of response generation. Not only is LLMLingua reducing prompt tokens by 10x, but at times it's even more!



Top comments (0)