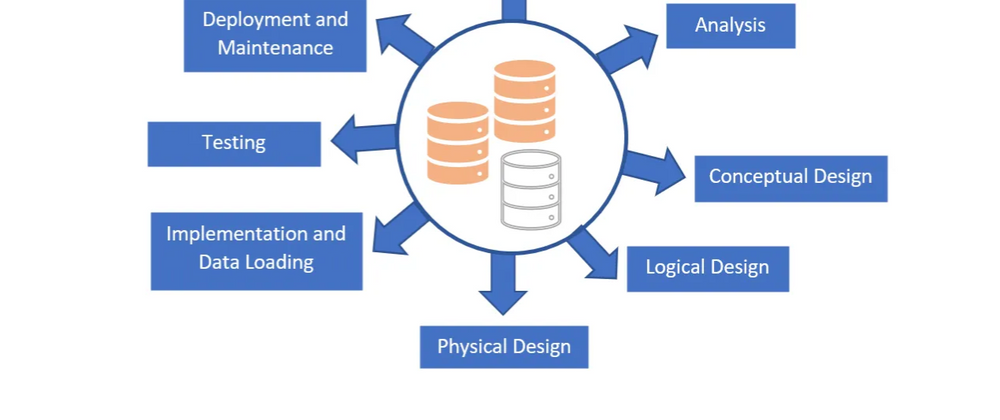
A brief overview of the eight steps in the database development life cycle.
If you were to build a new house, you certainly wouldn’t want to start with putting the walls up first without being prepared. You would want to talk to an architect to determine how big the house will be, how much it will cost, who will be the builders, how long it will take etc. And once this process is complete you could use your blueprint to begin construction on the house.
The same goes for building a database.
A database is a collection of related and organized data that is generally stored on a server or multiple servers for use. To build a database you need to start writing things down. Like the house, what you want is a set of documents to outline all the pieces, all the functionalities, and how to assemble them.
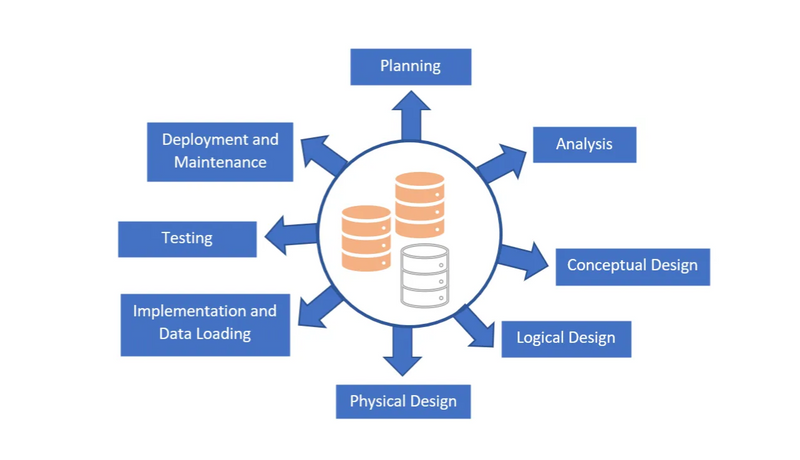
The Database Development Life Cycle (DDLC) is a process used in development to guide the creation of a database. This process includes 8 steps: Planning, Analysis, Conceptual Design, Logical Design, Physical Design, Implementation and Data Loading, Testing, Deployment and Maintenance.
If you Googled the DDLC process you probably noticed that there are different names and diagrams for it. Do not get caught up with which one is best; focus on understanding the process instead.
Now let’s look at those steps one by one.
Planning
Planning is when an organization decides whether there is a need for a database, determines the goals of the database, estimates the cost, debates feasibility etc. At the end of this step a mission statement and mission objectives should be clearly defined for the database.
Analysis
Analysis is also sometimes called “requirement gathering”. This step focuses on identifying all the tasks the database will be performing, and identifying all the user use cases for the system. This step requires a lot of research and collaboration with stakeholders (customers, product owners, end-users, employees…). All the information gathered should be stored in a document called requirement specifications.
Before you continue learning about the design phase, I must tell you that the next three steps are usually used for relational databases. Although most NoSQL databases focus on the physical design (or might use another design approach) the following steps can still be used in non-relational databases. The way you go about designing the models are different, but the same concepts apply. If you are interested you can take a look at the Apache Cassandra documentation on data modeling here.
Conceptual Design
In this step the requirement specifications are translated into a conceptual model of the database. The data is categorized into graphical representation of the entities needed and the relationship and dependencies between them.
Although the model represents the entire database it’s not very detailed. This model should be high level and easy to understand. The goal here is to visualize the entities, their fields, and clarify the connection between them.
Logical Design
Significantly more detail about each entity and the system as a whole is required in this step. You do not need to worry about how they will be physically implemented. Instead, focus on:
specifying all attributes for each entity listed in the conceptual model
specifying primary keys, foreign keys, clustering columns and query lines (for NoSQL DBs)
normalizing the database
applying integrity constraints
Physical Design
This step is the last in the design phase. The more work put into the previous step, the less work needs to be done here.
This step starts associating the model with a Database Management System. You should focus on:
converting your entities into tables, nodes or documents
assigning data types
following name conventionality to your specific database system
optimizing and validating the design before implementation
Denormalization might happen here
Basically, this model is the actual representation of your database. Note that there are tools you can use to help your design. You can use those tools to write your queries, or use an interface and see your specifications translated into a model. For instance, you have hackolade non-relational databases and QuickDBD for relational databases.
Implementation and Data Loading
Once you are sure your database design is solid and ready to be implemented you can install your database management system (DBMS), create your database, load data into the system (if you have any), integrate the database with another application, etc.
Testing
Now you are ready to do a full test of your database! This step is pretty straight forward. The goal is to make sure that everything works as expected. You, a testing team, or an automated system might find some anomalies that need fixing. That’s fine; nothing is perfect. That’s why there is a testing phase. Testing can be done automatically or manually, and it’s a good idea to test in multiple environments for better quality assurance.
Deployment and Maintenance
Once everything is confirmed to be working you should be deploying to a production environment. And - unless for some reason the database was created for a one-time use - there will be a need to maintain the database. There will be changes, bug fixes, etc.
While the processes for any changes, bug fixes, etc. may not take as long as when the database was being created, you will need to revisit those steps again and again and again. That’s why it’s called a cycle!




Top comments (0)