Today we will deep dive into learning how to tag documents using LLMs
Project Overview:
- Introduction
- Background
- Tools and Technologies
- Project Components
- How It Works
- Benefits
- Challenges and Considerations
- Future Directions
- Results
- Conclusion
For complete code, refer to Github repository
1. Introduction:
In this project, We are focusing on document classification for the given predefined entities. We have developed a comprehensive solution that segregates documents. we are looking to make the classification as smooth as possible using LLMs. Individuals who are sitting with a large number of files are the intended audience.
2. Background:
No need to manually read all the documents and classify them. This process takes a lot of time and human resources. Using this tool we can classify documents within a few seconds without having to worry about accuracy.
3. Tools and Technologies:
Python: the base programming language used across the project.
Gradio: is used to quickly build a web interface.
OpenAI models: Core LLMs to classify documents.
Langchian: is used to integrate all the services.
4. Project Components:
A) Web Interface: Gradio helps us to transform Python scripts into interactive data science/Machine learning web apps in minutes, instead of weeks with regular frontend tools. Build dashboards, generate reports, or create chat apps.
B) LLMs: We have utilized OpenAI models that are, like, super powerful and, you know, efficient in generating and understanding natural language texts. it is like, based on GPT (Generative pre-trained transformers) architecture. We have used the Openai GPT-3.5-turbo model in our project!
C) Integration: Langchain is an open-source LLM framework that is widely used in various applications like RAG, Query database, web scraping, chatbots, etc. It is used to integrate any LLM with any service out there, We have utilized the tagging chain pydantic from langchain.
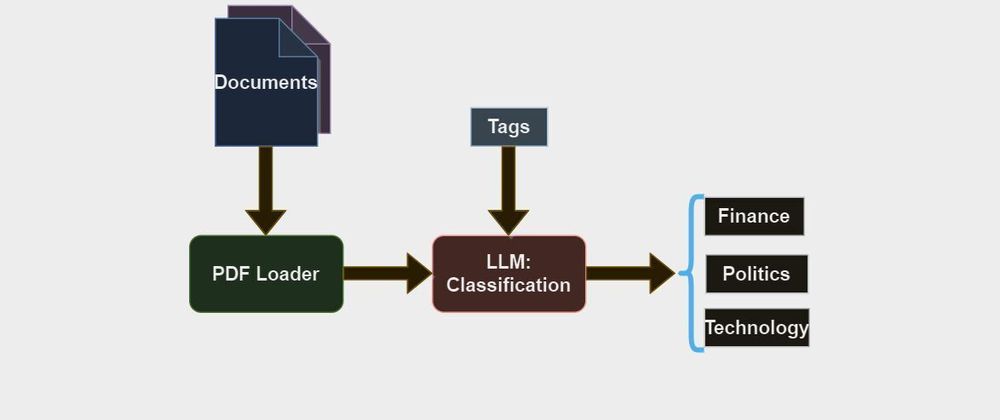
5. How It Works:
Gradio interface takes inputs as multiple documents/Files like PDF, Text, etc. as shown below.
import gradio as gr
entity = gr.Interface(
tagging,[gr.File(label="Files", file_count="multiple")])
These inputs are sent to the tagging function which iterates over the list of documents and extracts each document separately using pypdf loader. The extracted information from the documents and LLM object is passed as parameters to the tagging chain pydantic returns output to gradio interface.
from langchain.chains import create_tagging_chain_pydantic
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import PyPDFLoader
def tagging(file_paths):
llm = ChatOpenAI(temperature=0, model="gpt-4")
#pydantic chain which is key for tagging
chain = create_tagging_chain_pydantic(Tags, llm)
docs = ""
#Iterating over list of paths
for path in file_paths:
head = os.path.split(path)
loader = PyPDFLoader(path)
doc = loader.load()
docs += "FileName: "+str(head[1])+"\n"+str(chain.run(doc))+"\n\n"
return docs
6. Benefits:
Any individual who is sitting with thousands of documents can segregate their documents into corresponding folders within a few seconds without having to read a single line of the document. Documents can also be classified not only based on core content but also based on data time, size of the file, type of the file, etc.
7. Challenges and Considerations:
Input files should not be broken, corrupted, or Invalid. document loaders like pdfloaders in our program can only handle valid files. Sometimes invalid inputs leads to abrupt results.
8. Future Directions:
I have implemented this project on PDF documents, we can extend it to any document of our choice, we just need to modify the corresponding document loader function in langchain that's all. We can also incorporate more classifications on the files.
9. Results:
D1. About input document: It is the pay slip of an employee
Output:
FileName: Employee Pay Slip.pdf
Category='Finance'
D2. About input document: It is success payment receipt
Output:
FileName: SuccessReceipt.pdf
Category='Finance'
D3. About input document: PM Speech
Output:
FileName: PIB2003974.pdf
Category='Politics'
10. Conclusion:
Our project provides a unique solution for any individuals who want to classify their documents into predefined classes. It results in saving a lot of time by replacing manual intervention we can further customize this solution by add more document types to input and more classification entities to output.




Top comments (0)