Today we will deep dive into learning how to shortlist resume using LLM.
Project Overview:
- Introduction
- Background
- Tools and Technologies
- Project Components
- How It Works
- Benefits
- Challenges and Considerations
- Future Directions
- Questions asked
- Conclusion
For complete code, please visit Github repository
1. Introduction:
In this project, We are focusing on a resume shortlist. We have developed a comprehensive solution that shortlists the resumes within a few minutes. we have used LLMs to extract important skills from resumes and job descriptions to later compare them. Organizations that want to automate their shortlisting process can adopt this.
2. Background:
No need to manually go through all the resumes and shortlist them. The manual process takes a lot of time and human resources. Using this tool we can shortlist resumes within a few seconds without having to worry about false negatives.
3. Tools and Technologies:
Python: the base programming language used across the project.
Gradio: is used to quickly build a web interface.
OpenAI models: Core LLMs to classify documents.
Langchian: is used to integrate all the services.
Fuzzywuzzy: is used to match job description and resume
4. Project Components:
A) Web Interface: Gradio helps us to transform Python scripts into interactive data science/Machine learning web apps in minutes, instead of weeks with regular frontend tools. Build dashboards, generate reports, or create chat apps.
B) LLMs: We have utilized OpenAI models that are, like, super powerful and, you know, efficient in generating and understanding natural language texts. it is like, based on GPT (Generative pre-trained transformers) architecture. We have used the Openai GPT-3.5-turbo model in our project!
C) Integration: Langchain is an open-source LLM framework that is widely used in various applications like RAG, Query database, web scraping, chatbots, etc. It is used to integrate any LLM with any other service out there, We have utilized a pdf loader from langchain.
D) String Matching: FuzzyWuzzy is a library of Python that is used for string matching. It uses Levenshtein Distance to calculate the differences between sequences. We have used the ratio function from fuzzy-wuzzy to get the match percentage.
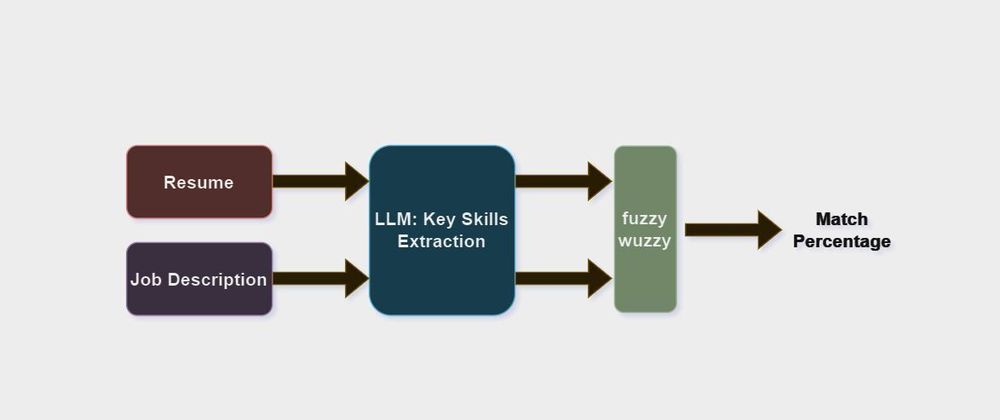
5. How It Works:
The gradio interface takes inputs like the resume as a file, job description as text, and criteria as a number- as shown below.
#gradio web interface
resume = gr.Interface(resume_shortlist,[gr.Textbox(label="Job Description:", value=""), gr.File(label="Resume:", file_count="single"), gr.Number(label="Match Criteria:"),],"textbox",title="Shortlist Resume",theme = "gradio/monochrome")
These inputs are sent to the resume shortlist function which extracts resume using pypdf loader. The extracted information from the resume is converted into a string. This resume string and job description text are passed separately to LLM. The response from LLM is passed as a parameter to the fuzzy-wuzzy ratio function which returns the percentage of match.
def resume_shortlist(desc, path, criteria):
question = "Extract all the key skills, experience, education
qualification from the text given"
doc1 = extract_skills(question+desc)
loader = PyPDFLoader(path)
docs = loader.load()
doc2 = extract_skills(question+docs[0].page_content)
match_percentage = fuzz.ratio(doc1, doc2)
It returns a match percentage which is validated with criteria, then it returns a corresponding message to gradio interface.
match_percentage = fuzz.ratio(doc1, doc2)
if match_percentage >= criteria:
return "This resume qualified for screening
round!\n\n"+"Match Percentage:
"+str(match_percentage)
else:
return "It does not match with our job
description!\n\n"+"Match Percentage:
"+str(match_percentage)
6. Benefits:
HR professionals who get thousands of resumes for a job post can utilize this tool to save time without having to read a single line of the resume and in some cases escalate it to developers to shortlist. we can also shortlist the top 10 or 20 profiles based on our requirements.
7. Challenges and Considerations:
The prompt engineering is crucial for maximizing the performance of LLM. Ambiguous prompts can lead to unexpected or undesirable responses, highlighting how crucially important clarity and precision are.
8. Future Directions:
I have implemented this project to take inputs as PDF(resume) and text(job description). we can extend it to any document of our choice, we just need to modify the corresponding document loader function in langchain that's all. We can also incorporate entity extraction to extract only required fields.
9. Results:
Inputs
Job Description:
In this exciting role as a AI/Data Science Engineer II you will have responsibility for transforming the way Quality utilizes data by creating opportunities to drive improved statistical consulting.
A Day in the Life
Designs, plans and executes statistical components of technical projects that impact the safety, efficacy, and marketability of Medtronic products.
Uses AI/ML to bring technology improvements relating to the life cycle of the product.
Business acumen (strong understanding of how business operates, and how to harness data and analytics to meet business needs)
Leverage strong understanding and working experience of the ML Ops lifecycle feature engineering, continuous training, validation, scaling, deployment, HA, DR, monitoring, and feedback loop to provide Run Sustain support for ML-based solutions.
Lead the Service Resolution Team (SRT) and leverage other roles like Data Engineer, Data Analyst and Visualization Engineers, to diagnose and resolve issues and ensure none to minimal impact to users of the solutions and to value of the solution. Priority should be on service restoration.
Defining the preprocessing or feature engineering to be done on a given dataset
Defining data augmentation pipelines
Training models and tuning their hyperparameters
Develops and/or applies AI/ML software (Python, Tensorflow, Pytorch, SK Learn package and other relevant packages)
Designing, developing, and implementing generative AI models and algorithms utilizing state-of-the-art techniques such as GPT, VAE, and GANs.
Analyzing the errors of the model and designing strategies to overcome them
Deploying models to production
Lead and participate on cross-functional projects
Present technical content to all levels of the organization including senior leadership
Summarizes and interprets data into tabular and graphical formats amenable to principles of statistical inference
Develops or provides specifications and directions on software development projects.
Must Have: Minimum Requirements
A baccalaureate degree and minimum of 8 years of relevant experience, or advanced degree with 5 years of experience.
Advanced degree in math, statistics, computer science, or related field
Experience in Life Science or Medtech Industry for 3 years
Extensive R or Python programming experience
Proficiency with a deep learning framework such as TensorFlow or Keras
Proficiency with Python and basic libraries for machine learning such as scikit-learn and pandas
Expertise in visualizing and manipulating big datasets
Proficiency with OpenCV
Familiarity with Linux
Ability to select hardware to run an ML model with the required latency
Nice to have:
Medical device domain knowledge
Project management experience
Demonstrated ability to communicate technical content to non-statisticians (written and verbal)
Role: Data Science & Machine Learning - Other
Industry Type: Pharmaceutical & Life Sciences
Department: Data Science & Analytics
Employment Type: Full Time, Permanent
Role Category: Data Science & Machine Learning
Education
UG: Any Graduate
PG: Any Postgraduate
Key Skills
Linux data science Project management Consulting Machine learning HealthcareAnalytics Monitoring Python
Resume: it is available in the data folder(1611292864525.pdf)
Match Criteria: 50%
Output:
It does not match with our job description!
Match Percentage: 38
10. Conclusion:
Our project provides a unique solution for professionals in organizations who want to automate the resume shortlist process. It is significant in saving a lot of time, they don't have to go through each resume and make decisions.


Top comments (0)