What is Keepalived, and how does it work?
Before we start how we are using Keepalived in our Hyperconverged scenario, let's first understand what is Keepalived and how does it work?
Keepalived is a free, open-source, high availability software based on VRRP protocol to build two or more nodes in failover mode. It is mainly used to implement load balancer and router failover. Keepalived uses LVS (Linux Virtual Server) kernel module and ipvsadm user-space utility for its operation. It has been released under the GNU GPL license.
High availability means having an infrastructure or application up and running with no downtime. Downtime can be caused by many things such as power failure, network failure, hardware failure, etc. To achieve high availability, we need to have some redundancy in place so that if one component of the cluster fails, another member can take over, and there is no downtime.
VRRP is a protocol that elects a controller node from a group of nodes (called a VRRP cluster), and the traffic is routed through the controller node. If the controller node goes down, another node in the cluster is elected as master, and traffic is routed. The protocol establishes virtual routers, which are abstract representations of numerous routers working as a group, such as Primary/Active and Secondary/Standby routers. Instead of an actual router, the virtual router is allocated to operate as a default gateway for participating hosts. If the router that is routing packets on behalf of the virtual router fails, it is promptly replaced by another physical router. This failover happens automatically without any manual intervention.
VRRP has the concept of Virtual IP, also called VIP. This IP address acts as a floating IP, meaning if the node is down where the VIP is present, VRRP protocol makes sure the VIP address is allocated to a healthy node. So, based on the health check of Virtual IP, VRRP determines the node health and elects an IP owner.
At a given time,
Only one host can own the IP address.
Keepalived uses a priority system to elect the new controller node. All nodes have priority defined; you can adjust this priority using the Keepalived configuration. This priority can be from 1 to 254, and the node with the highest priority (closest to 255) will become the master. A priority of 0 means that the node will never become the master, and a priority of 255 means that the node will always become the master (unless there is another node with a priority of 255). If two nodes have the same priority, the node with the highest IP address will be elected as the master.
Using Keepalived in a Hyperconverged OCP Cluster
In a Hyperconverged OCP cluster, we use Keepalived to provide high availability for,
- Kubernetes API (API VIP)
- OpenShift Router (Ingress VIP)
HA for Kubernetes API (API VIP)
In a Kubernetes cluster, the API server is the central point for all operations. All other components, such as kubelet, Kube-proxy, etc., communicate with the API server to perform their functions. So, it is essential to have high availability for the API server.
In a Hyperconverged OCP cluster, we use Keepalived to provide high availability for the API server by creating a virtual IP (VIP) address. This VIP address is assigned to one of the nodes in the cluster, and if that node goes down, another node takes over the VIP and becomes the new API server. This failover is transparent to the users and happens automatically without any manual intervention.
To use Keepalived for the API server, we need to install it on all nodes in the cluster. We also need to create a Keepalived configuration file on each node. This configuration file contains the details of the virtual IP address, priority of the node, etc.
HA for OpenShift Router (Ingress VIP)
OpenShift Router is a component that provides load balancing, SSL termination, and name-based virtual hosting. It routes the traffic from outside the cluster to the services within the cluster. OpenShift Router can be deployed as a pod or as a container on any node in the cluster.
Here is an example Keepalived static manifest and configuration file which we are using for API Server and Openshift Router,
kind: Pod
apiVersion: v1
metadata:
name: keepalived
namespace: openshift-openstack-infra
creationTimestamp:
deletionGracePeriodSeconds: 65
labels:
app: openstack-infra-vrrp
spec:
volumes:
- name: resource-dir
hostPath:
path: "/etc/kubernetes/static-pod-resources/keepalived"
- name: script-dir
hostPath:
path: "/etc/kubernetes/static-pod-resources/keepalived/scripts"
- name: kubeconfig
hostPath:
path: "/etc/kubernetes"
- name: kubeconfigvarlib
hostPath:
path: "/var/lib/kubelet"
- name: conf-dir
hostPath:
path: "/etc/keepalived"
- name: run-dir
empty-dir: {}
- name: chroot-host
hostPath:
path: "/"
initContainers:
- name: render-config-keepalived
image: quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:c1f0f7c54f0f2ecd38fdf2667651f95153a589bd7fe4605f0f96a97899576a08
command:
- runtimecfg
- render
- "/etc/kubernetes/kubeconfig"
- "--api-vip"
- "172.21.104.25"
- "--ingress-vip"
- "172.21.104.26"
- "/config"
- "--out-dir"
- "/etc/keepalived"
resources: {}
volumeMounts:
- name: kubeconfig
mountPath: "/etc/kubernetes"
- name: script-dir
mountPath: "/config"
- name: conf-dir
mountPath: "/etc/keepalived"
imagePullPolicy: IfNotPresent
containers:
- name: keepalived
securityContext:
privileged: true
image: quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:8c872154e89c7c361c882bcd6acff3ff97464e7f1a0311c631e9a939085e9934
env:
- name: NSS_SDB_USE_CACHE
value: "no"
command:
- /bin/bash
- -c
- |
#/bin/bash
reload_keepalived()
{
if pid=$(pgrep -o keepalived); then
kill -s SIGHUP "$pid"
else
/usr/sbin/keepalived -f /etc/keepalived/keepalived.conf --dont-fork --vrrp --log-detail --log-console &
fi
}
msg_handler()
{
while read -r line; do
echo "The client sent: $line" >&2
# currently only 'reload' msg is supported
if [ "$line" = reload ]; then
reload_keepalived
fi
done
}
set -ex
declare -r keepalived_sock="/var/run/keepalived/keepalived.sock"
export -f msg_handler
export -f reload_keepalived
if [ -s "/etc/keepalived/keepalived.conf" ]; then
/usr/sbin/keepalived -f /etc/keepalived/keepalived.conf --dont-fork --vrrp --log-detail --log-console &
fi
rm -f "$keepalived_sock"
socat UNIX-LISTEN:${keepalived_sock},fork system:'bash -c msg_handler'
resources:
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: conf-dir
mountPath: "/etc/keepalived"
- name: run-dir
mountPath: "/var/run/keepalived"
livenessProbe:
exec:
command:
- /bin/bash
- -c
- |
kill -s SIGUSR1 "$(pgrep -o keepalived)" && ! grep -q "State = FAULT" /tmp/keepalived.data
initialDelaySeconds: 20
terminationMessagePolicy: FallbackToLogsOnError
imagePullPolicy: IfNotPresent
- name: keepalived-monitor
securityContext:
privileged: true
image: quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:c1f0f7c54f0f2ecd38fdf2667651f95153a589bd7fe4605f0f96a97899576a08
env:
- name: ENABLE_UNICAST
value: "no"
- name: IS_BOOTSTRAP
value: "no"
command:
- dynkeepalived
- "/var/lib/kubelet/kubeconfig"
- "/config/keepalived.conf.tmpl"
- "/etc/keepalived/keepalived.conf"
- "--api-vip"
- "172.21.104.25"
- "--ingress-vip"
- "172.21.104.26"
resources:
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: resource-dir
mountPath: "/config"
- name: kubeconfigvarlib
mountPath: "/var/lib/kubelet"
- name: conf-dir
mountPath: "/etc/keepalived"
- name: run-dir
mountPath: "/var/run/keepalived"
- name: chroot-host
mountPath: "/host"
imagePullPolicy: IfNotPresent
hostNetwork: true
tolerations:
- operator: Exists
priorityClassName: system-node-critical
status: {}
Configuration:
global_defs {
enable_script_security
script_user root
}
# These are separate checks to provide the following behavior:
# If the loadbalanced endpoint is responding then all is well regardless
# of what the local api status is. Both checks will return success and
# we'll have the maximum priority. This means as long as there is a node
# with a functional loadbalancer it will get the VIP.
# If all of the loadbalancers go down but the local api is still running,
# the _both check will still succeed and allow any node with a functional
# api to take the VIP. This isn't preferred because it means all api
# traffic will go through one node, but at least it keeps the api available.
vrrp_script chk_ocp_lb {
script "/usr/bin/timeout 1.9 /etc/keepalived/chk_ocp_script.sh"
interval 2
weight 20
rise 3
fall 2
}
vrrp_script chk_ocp_both {
script "/usr/bin/timeout 1.9 /etc/keepalived/chk_ocp_script_both.sh"
interval 2
# Use a smaller weight for this check so it won't trigger the move from
# bootstrap to master by itself.
weight 5
rise 3
fall 2
}
# TODO: Improve this check. The port is assumed to be alive.
# Need to assess what is the ramification if the port is not there.
vrrp_script chk_ingress {
script "/usr/bin/timeout 0.9 /usr/bin/curl -o /dev/null -Lfs http://localhost:1936/healthz/ready"
interval 1
weight 50
}
{{$nonVirtualIP := .NonVirtualIP}}
vrrp_instance {{ .Cluster.Name }}_API {
state BACKUP
interface {{ .VRRPInterface }}
virtual_router_id {{ .Cluster.APIVirtualRouterID }}
priority 40
advert_int 1
{{if .EnableUnicast}}
unicast_src_ip {{.NonVirtualIP}}
unicast_peer {
{{ .BootstrapIP }}
{{range .LBConfig.Backends}}
{{if ne $nonVirtualIP .Address}}{{.Address}}{{end}}
{{end}}
}
{{end}}
authentication {
auth_type PASS
auth_pass {{ .Cluster.Name }}_api_vip
}
virtual_ipaddress {
{{ .Cluster.APIVIP }}/{{ .Cluster.VIPNetmask }}
}
track_script {
chk_ocp_lb
chk_ocp_both
}
}
vrrp_instance {{ .Cluster.Name }}_INGRESS {
state BACKUP
interface {{ .VRRPInterface }}
virtual_router_id {{ .Cluster.IngressVirtualRouterID }}
priority 40
advert_int 1
{{if .EnableUnicast}}
unicast_src_ip {{.NonVirtualIP}}
unicast_peer {
{{range .IngressConfig.Peers}}
{{if ne $nonVirtualIP .}}{{.}}{{end}}
{{end}}
}
{{end}}
authentication {
auth_type PASS
auth_pass {{ .Cluster.Name }}_ingress_vip
}
virtual_ipaddress {
{{ .Cluster.IngressVIP }}/{{ .Cluster.VIPNetmask }}
}
track_script {
chk_ingress
}
}
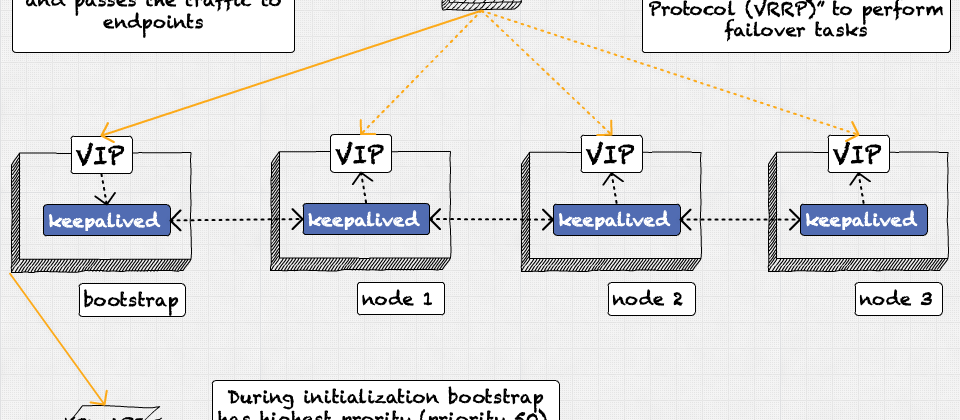
Keepalived Request Flow (During Openshift Bootstrapping Process)
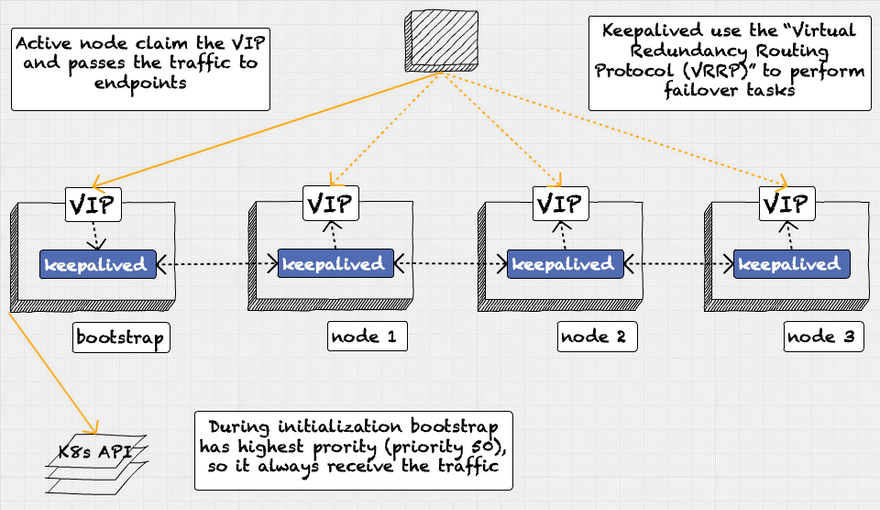
During initialization, we have a four-node cluster. The first node is the bootstrap node. The second, third, and fourth nodes are the controller nodes, which run the control plane pods. All four nodes have Keepalived installed and are configured with the same virtual IP address (VIP).
The bootstrap node is assigned the VIP and acts as the "controller" node when the cluster is first created. The other three nodes are in a "backup" state.
All three controller nodes pull the machine state from the bootstrap nodes during the bootstrap process. If the bootstrap node becomes unresponsive, those nodes will be unable to continue.
Once the bootstrap process is complete, one of the controller nodes will automatically take over the VIP and become the new "controller" node. After that, we can safely delete the bootstrap node.
Keepalived Request Flow (After bootstrapping process is complete)
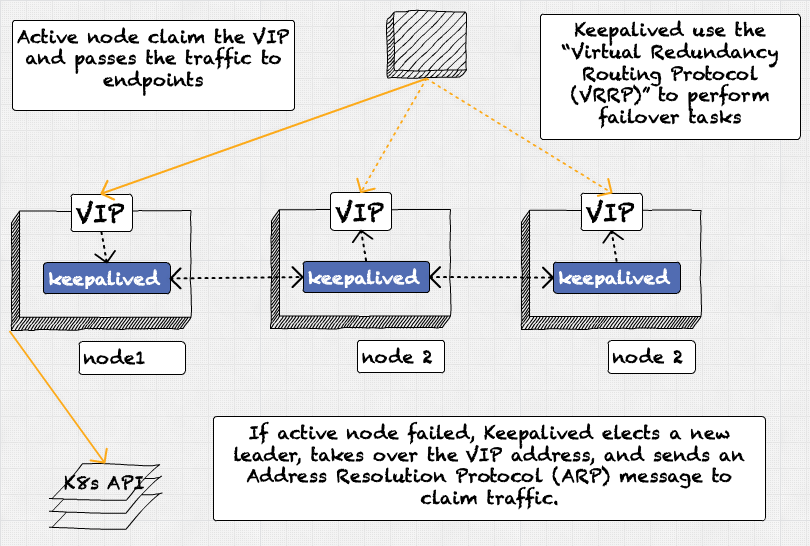
After the initialization is complete, we have a three-node cluster. All three nodes have Keepalived installed and are configured with the same virtual IP address (VIP).
Based on the configuration Keepalived uses the VRRP protocol to evaluate node health; the verification is done based on configured time intervals. Based on this verification, it elects a VIP owner and assigned IP to that node and marks the node as an active router. The traffic is always sent to the active endpoint if something happens to active nodes. Keepalived elects a new leader, takes over the VIP address, and sends an Address Resolution Protocol (ARP) message.
You have to configure separate checks for each service, so in our POC, we will configure the health check for k8s API and Ingress controller.
I think this is a good stopping point for Keepalived; let's move on to the next topic.


Top comments (4)
Hi Balkrishna, good article with deep dive on how to use static pods for setting up and using keepalived for HA Proxy and API endpoint. I have a quick question is it possible to configure and manage these static pods using MCO by just adding to the manifests.
Yes it is possible to use machineconfig to create static file. Simply create a file where kubelet is tracking and rest kubelet will start managing the pod.
Thanks for that, i was looking the static pod resources and there are some variables in haproxy config template. I was wondering how are these variables passed on to the haproxy config file, does installer passes these variables ?
There are 2 containers in that pod,
haproxy-monitorresolve the variable and produce the correct config, so that haproxy container can consume it.